L‘API gateway è il modulo software che, come il nome suggerisce, agisce da punto di entrata nel sistema a microservizi: ogni client che utilizza il sistema utilizza un protocollo diverso per comunicare e l’API gateway uniforma la risposta per tutti.
Interessante, ma andiamo oltre per il momento.
L’API gateway ha il compito di scovare la location e gli indirizzi dei microservizi, i quali cambiano perché cambia il numero di istanze e disponibilità degli stessi.
Va bene, comprendo questa necessità, ma soffermiamoci un attimo su un aspetto.
Fin dall’inizio della mia lettura l’API gateway sembrava somigliare a un modulo centralizzato che inoltra richieste a microservizi, valida la richiesta dell’utente e aggrega i dati. E’ davvero questo il suo compito?
No, è più complicato! Chi lo avrebbe immaginato?!
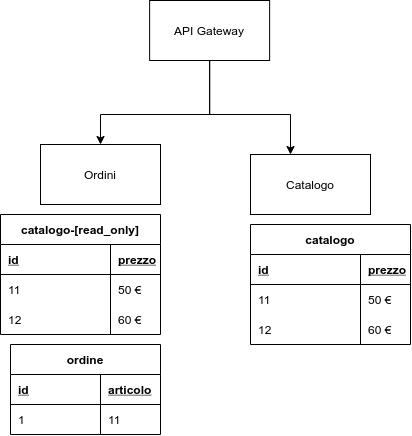
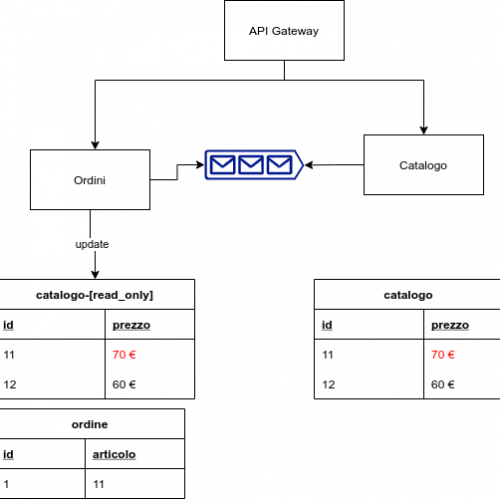
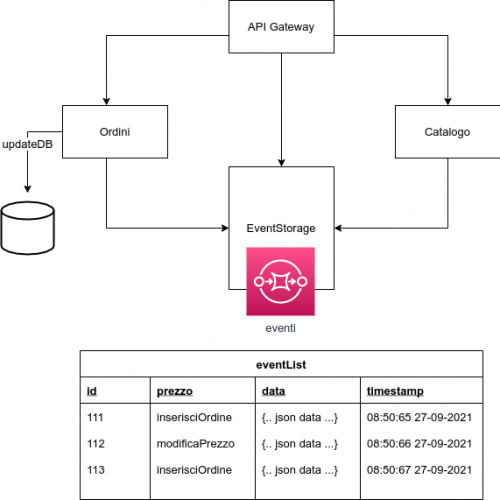
Infatti, in un sito di e-commerce, un “conto” è incrociare nell’API gateway i dati provenienti dal micro servizio che si occupa della gestione dell’anagrafica con quello che si occupa della gestione degli ordini di un utente; un altro è gestire tutta la logica di business relativa a un ordine e quindi lasciare al gateway il compito di ricavare il prezzo di un prodotto, aggiornare il magazzino e aggiungere un ordine.
Non è forse il caso di creare un micro servizio che appositamente aggreghi e finalizzi gli ordini?
Sì, colto nel segno!
In linea di massima le operazioni non associate a logica di business possono essere delegate all’API gateway, le restanti no. Ecco perché l’API gateway può aggregare dati non di interesse per il business e gestire autenticazione, accesso per ruoli e sicurezza.
Andiamo avanti… Anzi, un attimo!
Il medesimo API gateway può essere utilizzato in sistemi diversi? In fin dei conti, tipo di risposta, autenticazione, ruoli, sicurezza trasmissione sono caratteristiche di tutti i sistemi software!
Appunto per il futuro: argomento da riprendere!